

پاسخگویی به حوادث سایبری تفاوت بین کنترل آسیب و فاجعه کامل را مشخص میکند. این فرآیند ساختاریافته نه تنها حمله را متوقف میکند، بلکه سازمان را قویتر میسازد. در این راهنما، گامبهگام بررسی میکنیم چگونه تیمها حادثه را شناسایی، مهار، ریشهکن و از آن درس بگیرند، با تمرکز روی جزئیات عملی که بر اساس تجربیات واقعی و استانداردهای بروز مانند NIST SP 800-61 Revision 3 (منتشرشده در 2025) ساخته شده. این رویکرد، پاسخ سریع و مؤثر به تهدیدها را تضمین میکند و هزینهها را کاهش میدهد.

آنچه در این مطلب برنا مشاهده خواهید کرد:
چرا پاسخگویی به حوادث سایبری حالا حیاتی تر از همیشه است؟
تهدیدها پیچیدهتر شدهاند. طبق گزارش IBM Cost of a Data Breach 2025، متوسط هزینه جهانی یک نقض داده به ۴.۴۴ میلیون دلار رسیده، اما زمان شناسایی و مهار به پایینترین سطح ۹ سال اخیر، یعنی ۲۴۱ روز، کاهش یافته. این پیشرفت اغلب به خاطر ابزارهای مبتنی بر AI است، اما سازمانهایی که برنامه پاسخگویی به حوادث سایبری ندارند، هزینههای خیلی بالاتری پرداخت میکنند.
تهدیدهای رایج مثل ransomware هنوز غالب هستند. در Verizon DBIR 2025، بیش از ۴۴ درصد breaches شامل ransomware بود. یک حمله میتواند زنجیره تأمین را مختل کند، مثل آنچه در بخش بهداشت آمریکا دیدیم. بدون فرآیند منظم پاسخگویی به حوادث سایبری، سازمانها ساعتهای طلایی را از دست میدهند و آسیب گستردهتر میشود. اینجا حس واقعی فشار را احساس میکنید: صفحههای قرمز هشدار، تماسهای فوری و نیاز به تصمیمگیری سریع زیر نور کم اتاق سرور.
برای ارتقای امنیت شبکه، داشتن برنامه پاسخ قوی ضروری است. این برنامه نه تنها آسیب را کم میکند، بلکه با الزامات قانونی هماهنگ میشود.
آمادهسازی
همه چیز از آمادهسازی شروع میشود. NIST در نسخه ۲۰۲۵ راهنما، این مرحله را با Identify و Protect در CSF 2.0 همراستا کرده. اینجا تیم تشکیل میدهید، نقشها را مشخص میکنید و ابزارها را آماده میکنید.
اقدامات کلیدی در آمادهسازی:
- تشکیل تیم IR با نقشهای مشخص: هماهنگکننده، تحلیلگر فنی، ارتباطات خارجی و حقوقی.
- نوشتن playbook برای سناریوهای رایج مثل ransomware یا data exfiltration.
- سرمایهگذاری روی ابزارها: SIEM برای لاگگیری، EDR برای تشخیص endpoint، و backup های آفلاین.
- تمرین منظم tabletop یا simulation برای تست برنامه.
یکی از بهترین راهها برای تقویت این مرحله، خرید فایروال نسل بعدی (NGFW) است که ترافیک مشکوک را زودتر بلاک میکند. همچنین لایههای دفاعی مثل آنتیویروس پیشرفته را فراموش نکنید – خرید آنتی ویروس سازمانی با قابلیت behavioral detection، ریسک را کم میکند.
در این مرحله، حس آمادگی مثل بوی هوای تازه بعد از باران است: همه چیز مرتب، تیم هماهنگ و سیستمها آماده.
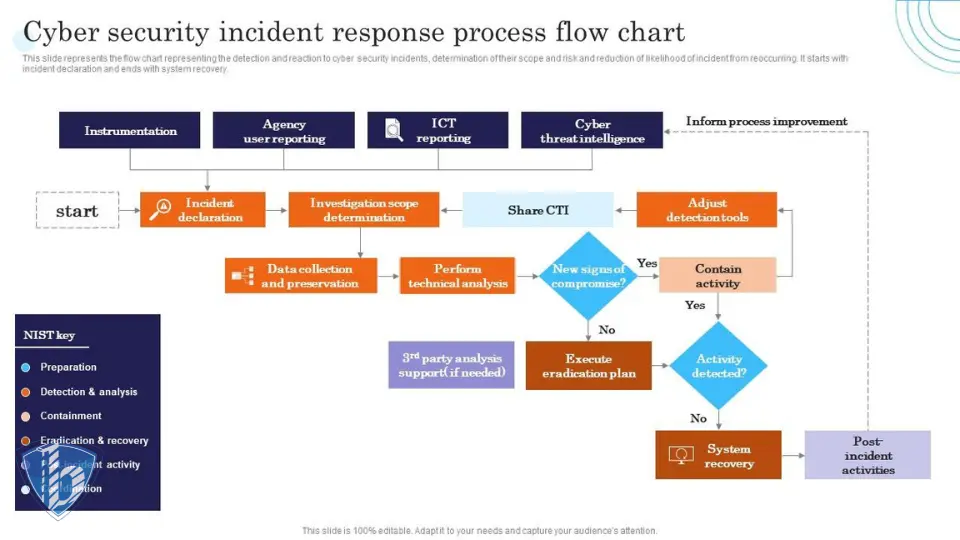
شناسایی حادثه
تشخیص زودتر، آسیب کمتر. در این مرحله (Detect و بخشی از Identify در NIST)، تمرکز روی جمعآوری و تحلیل نشانهها است.
نشانههای رایج که باید پیگیری شوند:
- افزایش غیرعادی ترافیک شبکه یا CPU usage در سرورها.
- لاگهای لاگین ناموفق مکرر از IPهای ناشناس.
- فایلهای ناشناخته با اکستنشنهای عجیب.
- هشدارهای EDR درباره فرآیندهای مشکوک مثل powershell abuse.
ابزارهایی مثل SIEM با correlation rules، این نشانهها را سریعتر آشکار میکنند. در گزارش IBM 2025، سازمانهایی که از security AI گسترده استفاده کردند، چرخه breach را تا ۸۰ روز کوتاهتر کردند.
وقتی هشدار میآید، اتاق پر از صدای کلیک ماوس و بحث سریع تیم میشود. اینجا triage انجام میدهید: حادثه واقعی است؟ تأثیرش چقدر؟ اولویتبندی بر اساس criticality داراییها.
برای تقویت تشخیص، امنیت سایبری لایهدار بسازید و تهدید intelligence را integrate کنید.
مهار حادثه
وقتی حادثه تأیید شد، مهار اولویت است (بخشی از Respond در NIST). هدف: جلوگیری از حرکت lateral attacker.
استراتژیهای مهار عملی:
- ایزوله کردن سیستمهای آلوده: قطع شبکه بدون قطع کامل عملیات.
- بلاک IPهای malicious در فایروال.
- تغییر credentials حساس اگر credential theft مشکوک باشد.
- در ransomware، پرداخت نکردن و تمرکز روی containment.
تعادل بین مهار سریع و حفظ evidence برای تحقیقات مهم است. گاهی segment شبکه را جدا میکنید تا attacker دسترسیاش را از دست بدهد.
حس این مرحله مثل خاموش کردن آتش کوچک قبل از فراگیر شدن است، تنش بالا، اما کنترلشده.
ریشه کنی تهدید
بعد از مهار، نوبت eradication است. اینجا attacker را کاملاً بیرون میکنید.
گامهای فنی ریشهکنی:
- اسکن کامل با ابزارهای updated EDR برای پیدا کردن backdoor یا persistence mechanism.
- پاک کردن malware، حذف حسابهای ساختهشده توسط attacker.
- patch vulnerabilityهایی که برای ورود استفاده شده (مثل Zero-day یا misconfiguration).
- بررسی third-party دسترسیها.
در NIST 2025، تأکید روی root cause analysis عمیق است تا recurrence جلوگیری شود. اینجا forensic tools مثل Volatility یا Autopsy برای memory analysis مفیدند.
برای جلوگیری از تکرار، بعد از این مرحله ارتقای امنیت شبکه با ابزارهای پیشرفته را در نظر بگیرید.
بازیابی عملیات
بازیابی حساسترین بخش است. سیستمها را برمیگردانید.
چکلیست بازیابی:
- تست integrity backup ها قبل از restore.
- monitor کردن سیستمهای restored برای نشانههای باقیمانده.
- gradual rollout: اول محیط test، بعد production.
- ارتباطات شفاف با stakeholders درباره زمان بازگشت.
در گزارش IBM، سازمانهایی که IR plan را منظم تست کردند، هزینه کمتری پرداختند. حس بازگشت مثل نفس راحت کشیدن بعد از بحران است – چراغها دوباره سبز میشوند.
درسهای آموخته شده
پایان حادثه، شروع بهبود است (Post-Incident Activity و Improvement در NIST).
فعالیتهای کلیدی پس از حادثه:
- برگزاری جلسه after-action review با تمام تیم.
- نوشتن report دقیق: چه شد، چرا، چه بهتر میشود.
- بروزرسانی playbook و ابزارها بر اساس یافتهها.
- اندازهگیری metrics مثل MTTD و MTTR.
این چرخه مداوم، پاسخگویی به حوادث سایبری را قویتر میکند.
ابزارها و فناوریهای ضروری در پاسخگویی به حوادث سایبری
جدول زیر ابزارهای کلیدی را مقایسه میکند:
| ابزار | کاربرد اصلی | مزیت کلیدی | مثال تجاری |
|---|---|---|---|
| SIEM | جمعآوری و correlation لاگها | تشخیص زودتر anomalies | Splunk, Elastic |
| EDR/XDR | تشخیص و پاسخ در endpointها | behavioral analysis | CrowdStrike, Microsoft Defender |
| SOAR | اتوماسیون playbookها | کاهش زمان پاسخ دستی | Palo Alto Cortex XSOAR |
| Threat Intel Platform | دریافت feed تهدیدها | contextual intelligence | Recorded Future |
| NGFW | کنترل ترافیک و segmentation | پیشگیری و مهار سریع | Cisco Firepower |
انتخاب ابزار مناسب با نیاز سازمان، بخشی از امنیت سایبری مؤثر است. گاهی خرید فایروال پیشرفته یا خرید آنتی ویروس EDR-based کافی است تا پایه قوی بسازید.
حمله ransomware به Change Healthcare
در فوریه ۲۰۲۴، گروه ALPHV/BlackCat به Change Healthcare حمله کرد. attacker ها از credential دزدیدهشده استفاده کردند و سیستمهای پرداخت و claims processing را encrypt کردند.
پاسخ سازمان:
- تشخیص اولیه سریع، اما گسترش حمله باعث اختلال nationwide در بیمارستانها و داروخانهها شد.
- مهار با ایزوله سیستمها و همکاری با forensic expertها.
- بازیابی تدریجی با restore از backupها، اما چند هفته طول کشید.
- هزینه نهایی بیش از ۲ میلیارد دلار (طبق گزارشهای ۲۰۲۵).
درس بزرگ: اهمیت MFA روی حسابهای privileged و segmentation شبکه. این مورد نشان داد چگونه ضعف در یک نقطه، کل اکوسیستم را مختل میکند و نیاز به پاسخگویی به حوادث سایبری هماهنگ با third-party ها را برجسته کرد.
بهترین شیوهها برای تقویت پاسخگویی به حوادث سایبری
- integrate AI برای تشخیص سریعتر، اما با governance درست.
- همکاری با MSSP برای ۲۴/۷ coverage.
- رعایت الزامات قانونی مثل گزارش به مقامات در زمان مشخص.
- سرمایهگذاری مداوم روی training تیم.
این شیوهها، سازمان را resilient میسازند.
سخن پایانی
با دنبال کردن این راهنمای گامبهگام بر اساس استانداردهای ۲۰۲۵، سازمانتان نه تنها از حملات جان سالم به در میبرد، بلکه قوی تر بیرون میآید. شروع کنید از ارزیابی برنامه فعلیتان و تقویت لایه های دفاعی مثل ارتقای امنیت شبکه. تهدیدها منتظر نمیمانند، اما شما میتوانید آماده باشید.





