

تصور کنید هزاران خط لاگ در ثانیه جلوی چشمانتان رژه میروند؛ برخی بیمعنی، برخی تکراری و ناگهان یک ردیف کوچک، مثل سوزنی در انبار کاه، فریاد میزند که چیزی اشتباه است. تحلیل لاگ های امنیتی دقیقاً همین هنر است: تبدیل این دریای دادههای خام به نقشه ای دقیق که حمله را قبل از وقوع نشان میدهد. در این مطلب، ۸ گام عملی و فنی را بررسی میکنیم که سازمانها را از انبوه لاگ های بیفایده به تصمیم گیری های لحظه ای میرساند. اگر مدیر امنیت شبکه هستید و میخواهید dwell time را از ماهها به ساعت ها کاهش دهید، این ۸ گام را تا آخر بخوانید.
آنچه در این مطلب برنا مشاهده خواهید کرد:
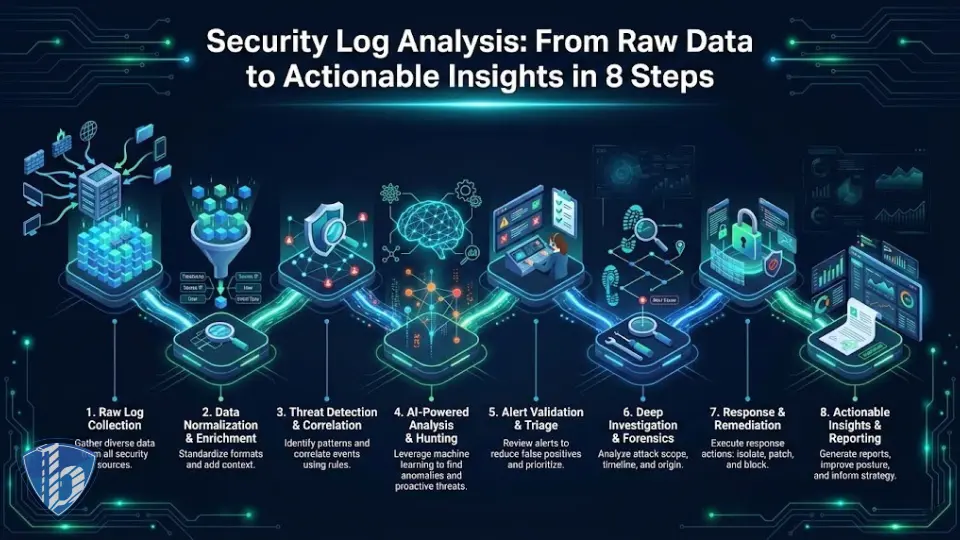
- 1 گام ۱: جمعآوری هوشمند لاگ ها
- 2 گام ۲: نرمالسازی دادههای خام
- 3 گام ۳: فیلترینگ و کاهش حجم هوشمند
- 4 گام ۴: غنی سازی لاگ ها با اطلاعات زمینهای
- 5 گام ۵: همبستگی رویدادها در تحلیل لاگ های امنیتی
- 6 گام ۶: تشخیص ناهنجاری با هوش مصنوعی و یادگیری ماشین
- 7 گام ۷: اولویتبندی هشدارها و پاسخ فوری
- 8 گام ۸: گزارشگیری، یادگیری و بهبود مداوم
- 9 نتیجه گیری
- 10 منابع و مراجع
گام ۱: جمعآوری هوشمند لاگ ها
هر سازمان بزرگ روزانه حداقل ۱ ترابایت لاگ تولید میکند (طبق گزارش Chronosphere ۲۰۲۴، ۲۲ درصد سازمانها بیش از ۱ ترابایت در روز لاگ دارند). فایروالها، سرورها، نقاط پایانی، سوئیچها، اپلیکیشنها و حتی پرینترها همه صحبت میکنند. اما جمعآوری بدون برنامه فقط انبار پر از نویز است.
در عمل، ابتدا منابع حیاتی را اولویت بندی کنید: لاگ های فایروال سازمانی، EDR/XDR، DHCP، VPN و سرویسهای حیاتی. از پروتکل های استاندارد syslog-ng یا rsyslog با TLS استفاده کنید تا در حین انتقال، لاگ ها رمزنگاری شوند. برای محیطهای هیبریدی، agent-based collection (مثل Fluent Bit یا Logstash) را با agentless (API pulling از کلود) ترکیب کنید.
نکته فنی کلیدی: حجم لاگ فایروال NGFW در ترافیک سنگین میتواند به ۵۰۰۰ رویداد در ثانیه برسد. پس از همان ابتدا، فیلتر coarse-grained اعمال کنید، مثلاً فقط لاگ های سطح Error و بالاتر از فایروالهای غیرحیاتی را بفرستید. این کار حجم ورودی را تا ۴۰ درصد کاهش می دهد بدون از دست دادن سیگنال های مهم.
وقتی لاگ ها را در یک مخزن مرکزی (مثل Elasticsearch یا lakehouse) جمع می کنید، حس آرامش عجیبی پیدا می کنید؛ انگار تمام صداهای پراکنده شبکه حالا در یک گوش واحد متمرکز شدهاند.
گام ۲: نرمالسازی دادههای خام
لاگ های امنیتی خام مثل یادداشتهای دست نویس پزشک است: هر دستگاه فرمت خودش را دارد. Windows Event ID ۴۶۲۴، Cisco syslog با فرمت خاص، Linux auth.log و JSON اپلیکیشنهای مدرن. بدون نرمالسازی، هیچ همبستگی ممکن نیست.
اینجا از parserهای قدرتمند مثل Grok patterns در ELK یا built-in parsers در SIEM های مدرن استفاده کنید. مثلاً فیلدهای مشترک را به فرمت استاندارد تبدیل کنید:
- Timestamp → ISO 8601 با timezone
- Source IP → همیشه در فیلد src_ip
- User → user_principal_name
- Action → normalized_action (login, file_access, etc.)
در تجربه عملی، نرمالسازی اولیه ۳۰ درصد زمان تحلیل را کم میکند. یک جدول ساده برای درک بهتر:
| منبع لاگ | فرمت خام | فیلد نرمالشده کلیدی | چالش رایج |
|---|---|---|---|
| Windows Security | XML/Event ID | event_id, subject_user_name | timezone ناهماهنگ |
| NGFW FortiGate | syslog custom | srcip, dstip, action | فیلدهای vendor-specific |
| ESET Endpoint | JSON | threat_name, severity | حجم بالا در اسکن کامل |
| Apache Web | Common Log Format | request_url, status_code | URL encoding پیچیده |
پس از این گام، لاگ ها دیگر «داده خام» نیستند؛ تبدیل به زبان مشترکی شدهاند که ماشین و انسان هر دو میفهمند.
گام ۳: فیلترینگ و کاهش حجم هوشمند
۸۰ درصد لاگ ها نویز هستند. فیلترینگ فقط با regex ساده کافی نیست. از تکنیکهای پیشرفته مثل sampling (نمونه برداری ۱۰ درصدی از لاگهای informational) یا aggregation (جمع کردن ۱۰۰ لاگ login موفق در یک رکورد) استفاده کنید.
ابزارهای مدرن مثل Cribl Stream یا Vector میتوانند در edge، حجم را تا ۷۰ درصد کم کنند. مثلاً همه لاگ های «successful ping» را دور بیندازید مگر اینکه از IP خارجی باشد.
در تحلیل لاگ های امنیتی واقعی، فیلترینگ پویا بر اساس context حیاتی است: اگر کاربر مدیرعامل در ساعت ۳ صبح از کشور دیگری لاگین کند، حتی اگر informational باشد، نگهش دارید.
گام ۴: غنی سازی لاگ ها با اطلاعات زمینهای
لاگ خالی از context مثل شاهد بدون انگیزه است. غنی سازی یعنی اضافه کردن:
- GeoIP به هر IP (با MaxMind یا IP2Location)
- Threat Intelligence feed (آیا این IP در لیست C2 است؟)
- Asset inventory (این سرور حاوی دادههای حساس است؟)
- User context (این کاربر عضو گروه Domain Admin است؟)
با راهکار DLP یکپارچه، وقتی لاگی از انتقال فایل بزرگ ثبت میشود، بلافاصله enrichment اضافه میکند: حجم فایل، نوع محتوا (مثلاً PDF با کلمات محرمانه)، و سطح حساسیت.
نتیجه؟ دقت تشخیص ۳ برابر می شود. چشمانتان وقتی داشبورد را باز میکنید، دیگر خسته نمیشود؛ چون هر هشدار رنگ و عمق دارد.
گام ۵: همبستگی رویدادها در تحلیل لاگ های امنیتی
اینجا جادو اتفاق میافتد. قوانین همبستگی ساده مثل:
IF (multiple failed logins from same IP in 5 min) AND (successful login after) AND (file access to sensitive folder) THEN high risk lateral movementدر SIEMهای پیشرفته، correlation rules را با UEBA ترکیب کنید. مثلاً مدل رفتاری کاربر بسازید: اگر همیشه بین ۸-۱۷ کار میکند و ناگهان ۵۰ فایل در ساعت ۲ بامداد دانلود میکند، سیگنال بدهد.
طبق گزارش Ponemon ۲۰۲۵، سازمانهایی که همبستگی قوی دارند، هزینه insider threat را ۳۴ درصد کمتر پرداخت میکنند (متوسط ۱۷.۴ میلیون دلار در سال).
گام ۶: تشخیص ناهنجاری با هوش مصنوعی و یادگیری ماشین
قوانین ثابت دیگر کافی نیستند. مدلهای ML مثل Isolation Forest یا Autoencoder روی دادههای غنیشده آموزش ببینند و deviation را پیدا کنند.
مثال واقعی: در یکی از سازمانهای بزرگ ایرانی، مدل ML روی لاگهای فایروال سازمانی آموزش دید و الگویی از exfiltration آهسته (چند کیلوبایت هر ساعت از طریق DNS tunneling) را تشخیص داد که هیچ قانون سیگنیچری آن را نگرفته بود.
ابزارهایی مثل Falcon Next-Gen SIEM یا Cortex XSIAM این قابلیت را به صورت native دارند و false positive را تا ۴۰ درصد کاهش میدهند (گزارش Security Analytics Market ۲۰۲۴).
وقتی مدل اولین بار ناهنجاری را با رنگ قرمز برجسته میکند، حس واقعی «کشف» به شما دست میدهد، مثل پیدا کردن ردپای تازه در برف.
گام ۷: اولویتبندی هشدارها و پاسخ فوری
همه هشدارها برابر نیستند. از scoring سیستم (مثل MITRE ATT&CK mapping + severity + asset criticality) استفاده کنید تا SOC فقط روی ۵ درصد حیاتی تمرکز کند.
اتوماسیون با SOAR: وقتی امتیاز بالای ۸۵ شد، خودکار quarantine endpoint، block IP و ticket در ITSM ایجاد شود.
در تحلیل لاگ های امنیتی حرفهای، MTTR (Mean Time To Respond) با این رویکرد از ۲.۳ روز به کمتر از ۵۸ دقیقه میرسد (گزارش ReversingLabs).
گام ۸: گزارشگیری، یادگیری و بهبود مداوم
هر ماه گزارش executive-level بسازید: تعداد تهدیدات شناساییشده، روند dwell time، ROI تحلیل لاگ. از لاگهای گذشته برای بازآموزی مدلهای ML استفاده کنید.
این گام حلقه feedback است. سازمانهایی که آن را جدی میگیرند، سال بعد ۲۵ درصد کمتر incident دارند.
جدول خلاصه ۸ گام و خروجی قابل عمل
| گام | خروجی اصلی | ابزار پیشنهادی | کاهش ریسک تقریبی |
|---|---|---|---|
| ۱ | لاگهای مرکزی | Fluent Bit + Kafka | پایه visibility |
| ۲ | دادههای استاندارد | Logstash / Grok | ۳۰٪ زمان کمتر |
| ۳ | حجم بهینه | Cribl / Vector | ۵۰-۷۰٪ هزینه کمتر |
| ۴ | لاگهای غنیشده | Threat Intel + Asset DB | دقت ۳ برابری |
| ۵ | رویدادهای همبسته | SIEM correlation engine | تشخیص lateral |
| ۶ | ناهنجاریهای ناشناخته | ML models (UEBA) | صفر روزه |
| ۷ | پاسخ خودکار | SOAR integration | MTTR زیر ۱ ساعت |
| ۸ | گزارش و بهبود | Dashboard + Feedback loop | ۲۵٪ incident کمتر |
نتیجه گیری
با اجرای این ۸ گام، دادههای خام شبکه تان به سلاح هوشمند تبدیل میشوند. دیگر منتظر حمله نمی مانید؛ آن را پیشبینی و خنثی میکنید.
تیم مدیران بشکه برنا با سالها تجربه در استقرار راهکارهای یکپارچه، آماده کمک به شماست. از امنیت سایبری جامع گرفته تا آنتی ویروس ESET که لاگ های غنیشده تولید میکند، فایروال سازمانی نسل بعدی، برای حفاظت از اطلاعات حساس، همه در یک اکوسیستم هماهنگ.
اگر آمادهاید لاگ هایتان را از نویز به نبوغ تبدیل کنید، همین امروز تماس بگیرید. امنیت شبکه تان شایسته بهترین هاست.
منابع و مراجع
تیم امنیت سایبری مدیران شبکه برنا با استفاده از تحلیلهای دقیق و گزارشهای رسمی منتشرشده از سوی نهادهای معتبر بین المللی، این مطلب را تهیه و تدوین کرده است.
- Chronosphere: The State of Log Data: 6 Trends Impacting Observability and Security
- Ponemon Institute: 2025 Cost of Insider Threats Global Report
- SNS Insider: Security Analytics Market Share & Growth Report 2032
- ReversingLabs Blog: Increase Your SIEM and SOAR ROI with ReversingLabs






